革新之翼已展翅——理想汽车揭开MindVLA自动驾驶新篇章。MindVLA,这一视觉-语言-行为的大规模模型,标志着机器人领域新范式的诞生,它将空间感知、语言理解和行为决策融合于一个模型之中。这个智能体不仅能够与人类用户对话,理解其意图,还能担任一位耳聪目明、无所不能的私人司机,为用户带来前所未有的驾驶体验。
2025年3月18日,在NVIDIA GTC全球技术盛会上,理想汽车的自动驾驶技术掌门人贾鹏,向全球展示了迈向L4级自动驾驶的钥匙——MindVLA架构。这一集成了空间、语言和行为智能的机器人模型,正将汽车从冷冰冰的钢铁机器转变为拥有认知能力的“私人司机”。

贾鹏强调:“MindVLA,作为机器人领域的创新模型,成功融合了空间智能、语言智能和行为智能。一旦物理世界与数字世界的结合模式得以实现,MindVLA将有能力推动多个行业的变革。MindVLA将把汽车从单纯的交通工具转变为一位忠诚的私人司机,它能够听懂、看见、找到所需,我们期望它能具备类似人类的认知和适应能力,成为一个能思考的智能体。”
全栈自研,MindVLA深度整合空间、语言及行为智能
基于端到端和VLM双系统架构的先进实践以及对前沿技术的深刻洞察,理想自主研发了VLA模型——MindVLA。VLA,作为机器人领域的新范式,赋予自动驾驶强大的3D空间感知、逻辑推理和行为生成能力,使得自动驾驶能够感知环境、思考并适应变化。
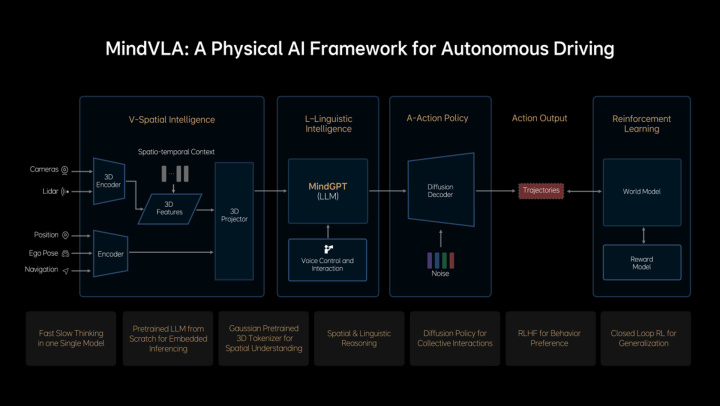
MindVLA并非简单地将端到端模型和VLM模型结合,而是每个模块都是全新设计。3D空间编码器借助语言模型和逻辑推理,生成合理的驾驶决策,并通过Diffusion模型优化出最佳的驾驶路径,整个过程在车端实时完成。
MindVLA六大关键技术,开创全新技术范式
MindVLA突破了自动驾驶技术框架设计的传统限制,采用了3D高斯这一优秀的中间表征,它具有丰富的语义承载能力和出色的3D几何表达,通过海量数据的自监督训练,大幅提升了下游任务性能。
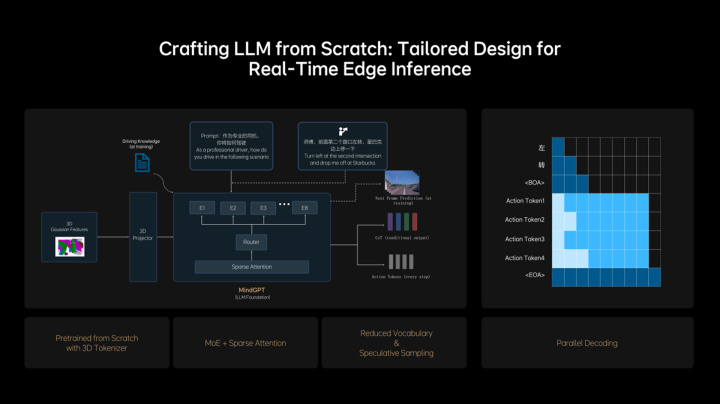
理想从零开始设计和训练了适合MindVLA的LLM基座模型,采用MoE混合专家架构,引入Sparse Attention实现模型稀疏化,在保证模型规模增长的同时,不降低端侧推理效率。基座模型在训练过程中融入大量3D数据,使其具备3D空间理解和推理能力。
...
(此处省略部分内容,以下为继续改写的内容)理想汽车通过创新的预训练和后训练方法,使MindVLA具备卓越的泛化能力和涌现特性,不仅在驾驶场景中表现出色,在室内环境也展现出了适应性和延展性。
MindVLA赋予汽车专职司机功能,重塑用户体验
MindVLA将为用户带来前所未有的产品形态和体验。搭载MindVLA的汽车将成为一位忠诚的私人司机,它能听懂用户的指令,如:“带我去超市”或“开慢点”,并能执行这些指令。

“看得见”功能意味着MindVLA能够识别各种标志和商店招牌,当用户在陌生地点找不到车辆时,只需拍下照片并发送给车辆,MindVLA就能找到并定位用户所在的位置。
“找得到”则意味着车辆能够自主地在各种环境中漫游,比如在地库或园区中寻找车位,无需依赖地图或导航信息。
...
(此处省略部分内容,以下为总结)随着MindVLA的推出,理想汽车不仅推动了技术创新,还在人工智能领域顶级学术会议和期刊上发表了大量论文,为技术发展贡献了重要力量。未来,理想汽车将继续致力于技术创新,连接物理世界与数字世界,致力于成为全球领先的人工智能企业。